Everything you need to release the full potential of your data.
The Evolution Toward an Alertless SOC
Security Operations Centers (SOCs) are evolving quickly, and traditional, alert-driven defenses just aren’t enough anymore. Today’s threats demand a smarter, more proactive approach. This report includes insights on the shortcomings of SOC alert management, the promise of AI in SOCs, and Devo’s vision for an Alertless SOC.
Leading the SOC: A Tactical Guide for SOC Managers
Whether you’re an experienced SOC manager or aspiring leader, this guide offers actionable insights on scaling processes, developing teams, recruiting talent, tracking performance, and advocating for tools to ensure your SOC’s success.
The Modern CISO: An Essential Guide for CISO Success
Discover insights from top CISOs on evolving leadership, navigating SEC regulations, and balancing cybersecurity with business strategy. Equip yourself to lead as a trusted advisor and mitigate legal risks effectively.
Navigating SIEM Consolidation: Three Must-Ask Questions
Surviving to Thriving: Navigating SIEM Complexity for MSSP Success
Read More
Devo + Detecteam: Engineering Confidence in Threat Detection
Learn how you can use Devo Exchange to extend the capabilities of your security team with on-demand content.
Rock the SOC: A Career Guide for Your First Analyst Role and Beyond
Kickstart your SOC analyst career with expert tips, frameworks, and guidance to land your first role, grow your skills, and navigate career challenges toward leadership success.
Devo Data Analytics Cloud
Discover how Devo Data Analytics Cloud can enable organizations to scale operations, optimize costs, and respond to threats in real time.
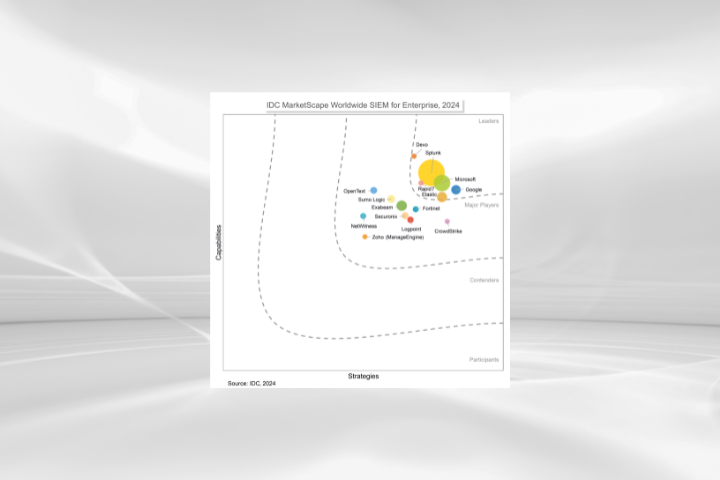
IDC MarketScape Worldwide SIEM for Enterprise 2024 Vendor Assessment
The Combined Power of Devo & CyberMaxx
Learn how CyberMaxx enables clients to proactively manage cyber risk with an innovative blend of MDR, Offensive Security, GRC, and Security Control Management.
The Combined Power of Devo & DeepSeas
Discover how DeepSeas achieved unparalleled scalability and flexibility in security operations with Devo’s SIEM solution.
Devo Threatlink™
Learn how Devo ThreatLink improves operational efficiency and threat response.
Surviving to Thriving: Navigating SIEM Complexity
Subscribe today to stay informed and get regular updates from Devo